0 集合介绍
集合
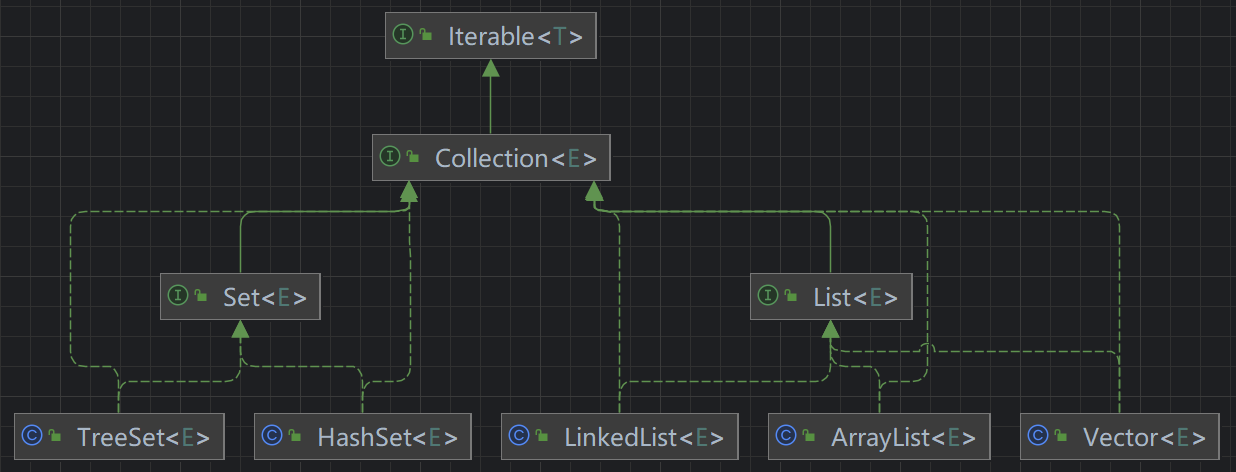
集合可以动态保存任意多个对象,且提供了一系列的操作对象的方法。集合主要是两组:
- [>]
单列集合:Collection接口有两个重要子接口ListSet(单列集合就是存一个单独的元素)- [>]
双列集合:Map接口实现的子类就是 (存放元素的形式为 K-V)
1 Collection接口
1.0 ArrayList 常用方法
以下是
ArrayList常用的一些方法,但根据以上类的关系图,可以发现许多类都实现了同一个接口,所以这些类的方法都 大同小异 ,可以互相参考
| 方法 | 说明 |
|---|---|
add() | 添加单个元素 |
remove() | 删除指定元素 |
contains() | 查找某个元素是否存在 |
size() | 获取元素个数 |
isEmpty() | 判断是否为空 |
clear() | 清空 |
addAll() | 添加多个元素 |
containsAll() | 查找多个元素是否都存在 |
removeAll() | 删除多个元素 |
📌📌📌 只要实现了
Collection接口的类,都可以使用Iterator迭代器进行遍历(生成迭代器代码,IDEA中的代码模板:itit)
😎😎😎
增强for循环可以用来取代迭代器的写法,其底层还是 迭代器 (IDEA快捷:I)
⚡ ArrayList 中维护了一个 Object 类型的数组来存储数据
⚡ 创建 ArrayList 如果使用的是无参构造器,则 初始化容量为0,第一次添加元素时再扩容至10,之后每次不够再扩容至当前大小的 1.5 倍
1.1 Vector
🐼 通过集合介绍可以知道,Vector 和 ArrayList 一样,都实现了 List 接口
📌 最大的区别在于:ArrayList 不安全,效率高 ,但 Vector 安全,效率不高
🤺 在扩容倍数上有差距,ArrayList 每次扩容 1.5 倍,Vector 每次扩容 2 倍
1.2 LinkedList
🌟 LinkedList 底层实现了双向链表和双端队列的特点
- 可以添加任意元素,包括
null - 线程不安全,没有实现同步
- 底层实现的双向链表中,维护两个属性
first和last,分别指向了首节点和尾节点 - 每个节点是一个
Node对象,里面维护了prev前指针、next后指针、item元素这些属性 LinkedList🆚ArrayList,ArrayList底层为可变数组,LinkedList底层为双向链表;ArrayList增删效率较低,改查效率高;Vector增删效率较高,改查效率低
2 Set接口
Set
📌
Set代表的是集合,所以其特点有:无序,且没有索引;不允许重复元素,所以最多只能有一个null。
2.0 HashSet
- 🖇️
HashSet实现了Set接口,所以接口的特点它也有HashSet其底层其实是HashMapHashSet不保证元素有序,这取决于hash后,再确定索引结果- 📌📌📌关于加入元素
add()方法的细节:1>add()方法里调用了map.put()方法,该方法如果加入成功,则返回null,不成功则返回与之重复的对象。add()方法里将返回结果与null进行比较,通过boolearn类型表现添加元素成功与否的结果2>map.put(e, PRESENT)调用时是这个样子的,其中e就是我们要添加的对象,不过 hash 表里用Node这个类对象来进行存储,这个对象需要<K, V>,所以传入一个PRESENT,这是一个static final的Object对象,所以传入的都一样,起到一个占位的作用3>put()方法里调用了putVal(hash(key), key, value, false, true)方法,这里通过我们要添加的对象key计算一个 hash 值4>这个hash(key)的计算并不是简单的hashcode()的值,具体为:(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16),主要目的就是减少冲突5>putVal()方法里涉及到了HashMap真正的存储结构:数组+链表+红黑树6>数组+链表其实就是拉链法的一个结构,初始这个数组的长度为16,添加的元素通过计算的hash值来确定在该数组中的存储索引,计算索引相同元素,则在该位置开始,通过链表的形式来进行存储7>数组长度的扩容有一个阈值机制,当hashSet里存储的元素个数(不是指数组里元素的个数)已经达到了当前数组长度的0.75时,就进行扩容,每次扩容是在当前长度的基础上翻一倍8>当一个链表的长度达到了8,则会开始考虑用红黑树的结构来代替链表的存储结构,真正转为红黑树需要同时满足:① 有链表长度等于或超过8;② 数组的长度大于或等于64。同时满足才会用红黑树,如果第二条不满足,则会对数组长度进行扩容9>📌📌📌判断元素相同的机制 :① 计算出的 hash 值相同;② 两个元素引用相同或通过equal()方法比较是相同的。只要同时满足这两个条件,就认为这是一个重复元素,就不能加入🚩🚩🚩(重要,最根本的机制)
2.1 LinkedHashSet
- 🖇️
LinkedHashSet是HashSet的子类- 其底层是一个
LinkedHashMap,底层维护了一个数组+双向链表 - 物理上还是分开存的,但是通过双向链表,让我们输出的时候符合
插入顺序 - 该类也实现了
Set接口,所以也符合该接口的特点
- 其底层是一个
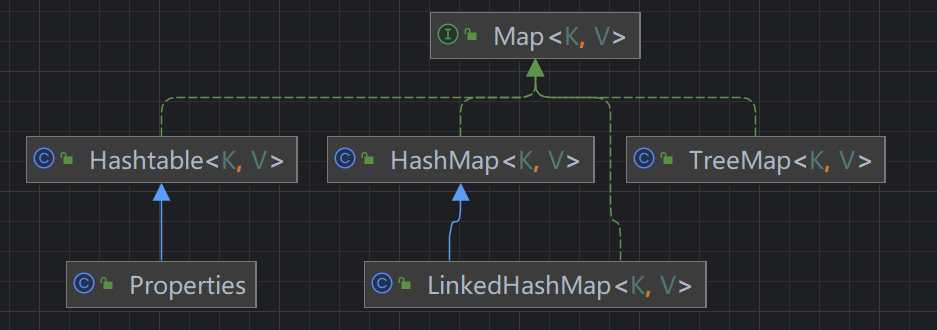
3 Map接口
- ⚡
Map接口和Collection接口并列存在,用于保存具有映射关系类型的数据:<K, V> HashSet的只存 单个元素 ,但之前源码解析里提到,其底层实现方式就是HashMap,主要是将 单个元素 存到K的位置,而V的位置统一使用了一个static final的Object的对象进行占位- 🌟🌟🌟
Map接口的特点:Key和Value可以是任何 引用类型 的数据,会封装到HashMap$Node对象中Map中key不允许重复,原因见2.1小节HashSet部分的源码分析,如果通过Key判断为重复对象,会使用 覆盖机制 将原来的对象替换Value可以重复null可以作为key,也可以作为value- 实际常用
String作为key - 为了方便遍历,
HashMap会将存入的K-V封装成一个entry放到一个entrySet的集合中去,实际上,不是拷贝,只是在这个集合中存储了对应K-V的一个 引用 entrySet里,key是存到Set里的,value是存到Collection里的。可以分别通过KeySet()和values()方法查看
| 方法名 | 描述 |
|---|---|
put() | 添加 |
remove() | 根据 key 移除元素 |
get() | 根据 key 获取对应的 value |
size() | 获取元素个数 |
isEmpty() | 判断是否为空 |
clear() | 清空表 |
containsKey() | 查看某个 key 是否存在 |
3.0 HashMap
HashMap其特点在2.0小节时已经讲过了,一点点区别在于HashSet是调用了add方法,在方法里调用了HashMap的put()方法,所以这里直接调用put()方法即可。此外:HashMap线程不安全
3.1 HashTable
- 🎞️ 其存放的元素形式仍是
<K, V> - ❌键和值都不允许为
null - 📌线程安全
- ⚡键值相同时仍然是 替换机制
- 🆚
HashMap底层通过HashMap$Node来存储,HashTable底层通过HashTable$Entry来进行存储。两者功能一样,结构也十分类似- 初始化数组大小为
11 - 数组的扩容阈值也同样是
0.75 - 扩容机制为当前数组长度 翻倍 然后再 加一
HashTable和HashMap相比,效率较低
- 初始化数组大小为
3.2 Properties
- 继承自
HashTable,并实现了Map接口 - 常用于读取
xxx.properties配置文件,将配置信息加载到类对象中进行读取和修改
4 使用总结
- 一组单列对象:
Collection接口- 允许重复:
List- 增删多:
LinkedList,底层是双向链表 - 查改多:
ArrayList,底层 Object 类型的可变数组
- 增删多:
- 不允许重复:
Set- 无序:
HashSet,底层还是 HashMap - 有序:
TreeSet - 插入和取出的顺序一致:
LinkedHashSet,维护数组+双向链表
- 无序:
- 允许重复:
- 一组双列对象:
Map接口- 键无序:
HashMap,底层 数组+链表+红黑树 - 键排序:
TreeMap - 键插入和取出顺序一致:
LinkedHashMap - 读取配置文件:
Properties
- 键无序:
5 TreeSet&TreeMap
TreeSet底层就是TreeMap- 如果创建时使用的是无参构造器,这两个对象 仍然是无序的
- 需要按照自己的需求排序,可以在创建对象时传入一个
Comparator()对象,该对象必须实现compare接口,在该接口中定义排序规则