Chinese-LLaMA-Alpaca-3
Chinese-LLaMA-Alpaca-3在
Meta发布的原版LLaMA模型的基础上扩充了中文词表并使用中文数据进行了二次训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。另一方面,因为Meta发布的LLaMA模型禁止商用,并没有正式开源模型权重,需要进行申请,所以该项目仅发布了LoRA权重,可以理解为LLaMA的一个补丁,需要合并参数后使用。
0 前言
📌 使用📃Text-Generation-WebUI与 LLaMA 模型进行交互的话,可以下载原版 LLaMA 模型参数与 LoRA 权重,然后进行分别加载,合并模型参数并不是必选项。
1. 模型参数的合并与转换
参考文档:官方Wiki 参考视频:bilibili大学
1.1 权重参数下载与解压
首先需要下载原版Llama模型的权重参数:LLaMA-7B ,llama-13b
现在第一次跑,我先只下载 LLaMA-7B 的权重参数,放到服务器下如下:
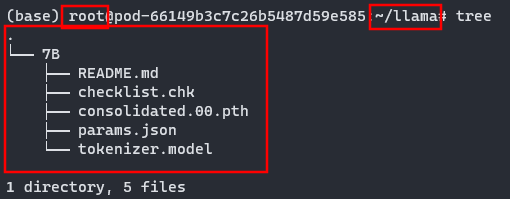
之后进入Chinese-LLama-Aplaca仓库下载微调过后的 LLaMA 和 Alpaca
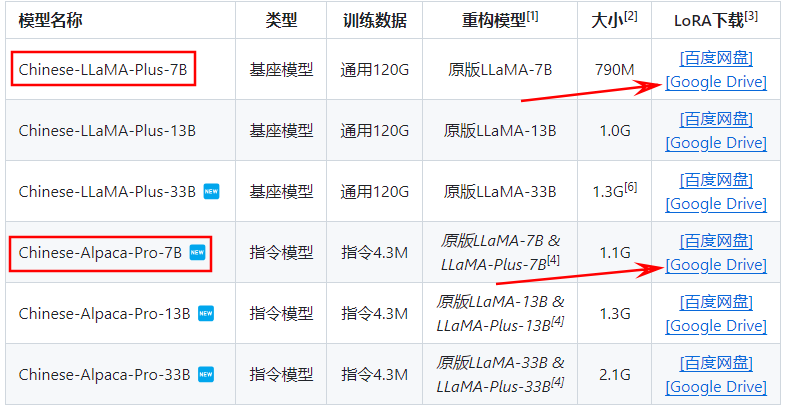
手动下载压缩包然后上传到实例,此时文件所在目录为:/root/sj-tmp/ ,我们在 /root/llama 路径下执行以下解压命令:
unzip /root/sj-tmp/chinese_llama_plus_lora_7b.zip -d ./chinese_llama_plus_lora_7b
unzip /root/sj-tmp/chinese_llama_plus_lora_7b.zip -d ./chinese_llama_plus_lora_7b解压完成后目录内容如下图所示:
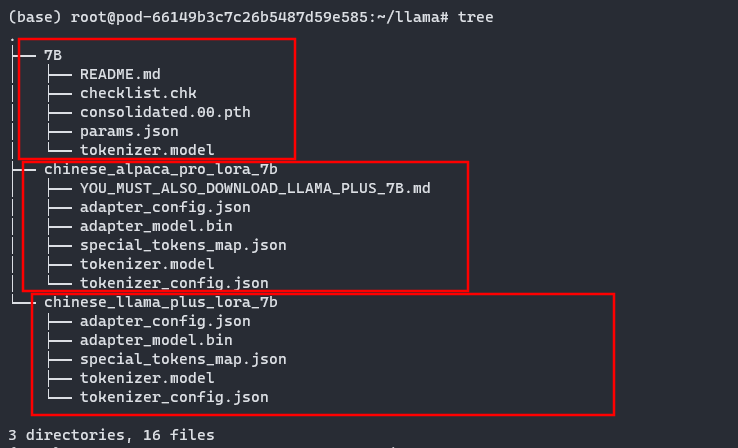
1.2 拉取仓库和安装环境
先拉取最新的仓库,我直接拉取到 /root 目录下:
git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca.git仓库拉取完成后创建需要的虚拟环境
conda create -n Chinese-LLaMA-Alpaca python==3.10
conda activate Chinese-LLaMA-Alpaca
cd Chinese-LLaMA-Alpaca/ # 进入拉取的仓库目录
pip install -r requirements.txt # 安装依赖下载转换脚本,该脚本可以将原版的 LLaMA 参数文件转换为 huggingface 格式。因仓库文件太多,所以我们单独下载转换脚本即可【转换脚本下载地址】,下载完成后上传到服务器的 /root 目录下:
1.3 执行转换脚本
执行转换脚本前,将7B/tokenizer.model文件放到7B同级目录下
mv ./7B/tokenizer.model ./
--input_dir 指定的是原版参数所在的文件夹内,这里不用指定到 7B ,指定到 /root/llama 即可,--model_size 设置模型大小,这里指定 7B,剩余文件就能定位到 /root/llama/7B 文件夹内,--output_dir 存放转换好的 HF版 权重(⚡可以执行会出错,后续有问题解决办法,可以先执行解决办法防止报错⚡)
python convert_llama_weights_to_hf.py \
--input_dir /root/sj-tmp/llama \
--model_size 7B \
--output_dir /root/sj-tmp/llama/7B_hf❌执行以上代码首先遇到了如下问题:
ImportError:
LlamaConverter requires the protobuf library but it was not found in your environment. Checkout the instructions on the
installation page of its repo: https://github.com/protocolbuffers/protobuf/tree/master/python#installation and follow the ones
that match your environment. Please note that you may need to restart your runtime after installation.💡解决(我安装最新的版本会报错,提示安装该版本或更低的版本):
pip install protobuf==3.20.0转换需要一定时间,转换完成后输出文件夹内容如下:
1.4 合并LoRA权重
可以进行单LoRA权重合并,需要的话自行参考官方Wiki,我这里进行的是多LoRA权重合并
参数说明:
--base_model:存放HF格式的LLaMA模型权重和配置文件的目录--lora_model:中文LLaMA/Alpaca LoRA解压后文件所在目录- 📌两个LoRA模型的顺序很重要,不能颠倒。先写LLaMA-Plus-LoRA然后写Alpaca-Plus/Pro-LoRA
--output_type:指定输出格式,可为pth或huggingface。若不指定,默认为pth,我们指定为huggingface--output_dir:指定保存全量模型权重的目录,默认为./
开始合并权重,这里我们使用新脚本
cd /root/sj-tmp/Chinese-LLaMA-Alpaca/
python scripts/merge_llama_with_chinese_lora_low_mem.py \
--base_model /root/sj-tmp/llama/7B_hf \
--lora_model /root/sj-tmp/llama/chinese_llama_plus_lora_7b,/root/sj-tmp/llama/chinese_alpaca_pro_lora_7b \
--output_dir /root/sj-tmp/llama/7B_full_model \
--output_type huggingface合并完成后新的目录结构如下:
2. 模型推理
2.1 Transformer原生推理
Transformer原生推理
教程链接 ,仅用该方式做测试 ,官方要求:
CPU运行7B确保有32G内存,GPU运行7B确保有20G显存(测试结果:显存使用14GB左右)
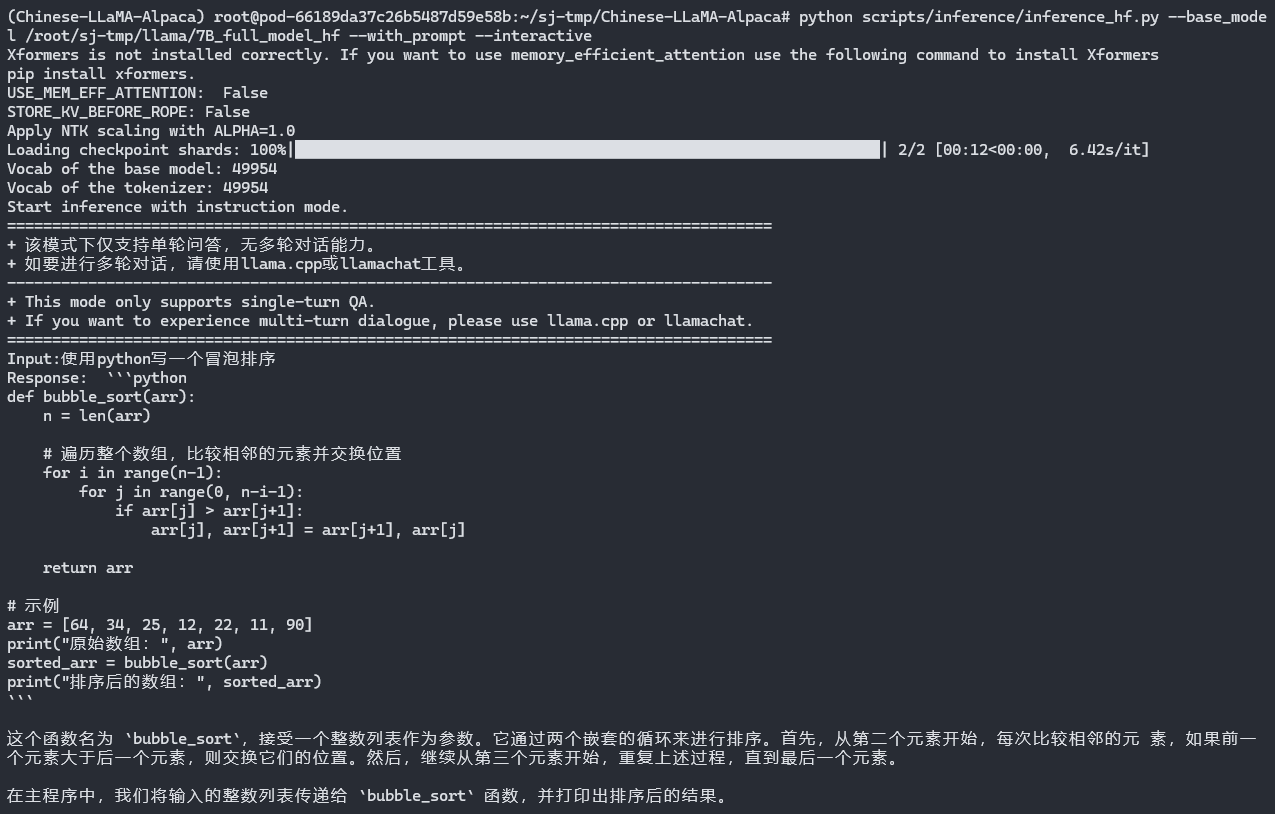
python scripts/inference/inference_hf.py \
--base_model /root/sj-tmp/llama/7B_full_model \
--with_prompt \
--interactive效果如图:
❌ 如果提示
TypeError: not String,引发该问题可能是终端输入汉字后,输入错误,使用退格键删除造成的异常
2.2 Text-Generation-WebUI
该项目的部署可参考📃Text-Generation-WebUI进行部署,这里仅在仓库克隆时重命名为 llama-webui,项目启动环境也重新创建了一个 llama 环境安装相关依赖。然后将我们合并好的参数模型直接放到该项目的 models 目录下,这里我将合并后的参数重命名为 merged_chinese_alpaca_pro
python server.py --model merged_chinese_alpaca_pro --listen --listen-port 8080